Merci @Animal. J'avais déjà cette option de décochée. Depuis mon problème est que les property access syntaxes s'affichent encore dans l'auto-complétion sauf à faire deux CTRL + ESPACE... Et qu'ils s'affichent à la place des appels normaux.
Mon besoin est donc de les faire disparaître de cette liste. Or, même en activant l'apprentissage des styles d'auto-complétion par machine learning, impossible de les virer. Cela semble être un truc hard-codé dans l'outil que l'accès à une méthode doit d'abord être proposé comme à accès à un attribut.

Pour ceux qui pensent que les règles Ktlint sont loin d'être parfaites (c'est mon cas) et qui voudraient se lancer dans leur propre Kotlin linter (je manque de temps).
Je n'ai pas encore migré nos projets mais le gain en temps de compilation semble formidable.
Voici le gain sur un projet cleané :

Et le gain sur un projet déjà compilé avec le build incrémental activé :

Je pense que je vais attendre le prochain patch de correctifs (car il y en aura sûrement) et je migrerai à ce moment-là.
Dash est un super environnement d'exécution pour le sous-ensemble POSIX de Bash. Il est portable, hyper rapide, consomme moins de 1 Mo de RAM. Bref un très bon outil.
Par contre, la syntaxe de Bash / Dash est error-prone au possible. D'autant qu'en dehors des outils classiques d'unix (grep, sed, awk, wget/curl) il y a peu de lib qui soient utilisables.
Bref, pour faire de petites choses comme lancer sa JRE ou filtrer des fichiers why not, mais en dehors de ça, ça me fait toujours hésiter.
Et ce matin je découvre que Kotlin peut être utilisé en tant que langage de scripts. Il suffit d'avoir installé dans notre PATH l'utilitaire kscript disponible ici et nous pouvons commencer à écrire ce genre de choses :
#!/usr/bin/env kscript
println("Hello, World!")Ensuite un petits chmod u+x sur notre fichier qui pourra se lancer en tapant :
./mon-script.ktsEt c'est super bien ça !
Kotlin progresse encore pour atteindre 1,18% de part de marché.
J'ai mis à jour ce post afin de montrer l'évolution. 14 places en 1 an c'est beaucoup. Je pense que Kotlin est en train de manger les parts de Java et le phénomène s'accélère.
Par contre qu'arrivera-t-il à la JVM lorsque Java ne sera plus utilisé et que Kotlin l'aura remplacé ?
Pour moi, la JVM devrait se transformer en moteur d'exécution et plusieurs langages tourneront dessus.
D'ailleurs c'est le projet d'Oracle avec GraalVM qui est déjà polyglotte et marche très bien.
Je travaille en ce moment sur deux projets, un en Java/Kotlin pour des clients, un second en Rust pour des besoins internes, et j'ai réalisé la chose suivante :
- En Java/Kotlin, le langage est fait pour vous aider mais vous allez vous battre contre les frameworks.
- En Rust, les frameworks sont faits pour vous aider mais vous allez vous battre contre le langage.
C'est incroyable à quel point le borrow checker vous pousse à écrire du code procédurale et mécaniquement intestable. Dès l'instant où l'on souhaite passer par des traits tout devient ultra compliqué. Dernièrement je me suis faite avoir en utilisant des Rc et des RcCell sur un code qui allait devenir multi-thread #Horreur
Pour moi, casser le couplage entre deux composants via une interface/trait est IN-DIS-PEN-SABLE mais Rust pousse à définir des structures comme contrat d'interfaçage principal entre deux pans de code.
Forcément, le langage se transforme en enfer dès l'instant où l'on souhaite dépendre d'un trait et non d'une structure (c'est pourtant le 'I' de SOLID, dépendre des Interfaces mais pas des Implémentations).
En même temps je l'avais déjà dit par le passé, le paradigme fonctionnel pur est un cancer métastasé car l'expressivité de la syntaxe donne le sentiment que des tests ne sont pas nécessaires or c'est toujours faux.
Et j'ai suffisamment souffert de Java dans ma vie pour haïr le fait de devoir mocker/instancier/déclarer quarante-douze-mille trucs avant de pouvoir tester une simple fonction.
Bref, deux ans sur Rust à temps partiel et je me vois retourner dans le RustBook tous les 4 mois pour y chercher un truc #Pénible alors qu'en Kotlin ça ne m'arrive jamais.
Un article qui montre comment invoquer du JS depuis du code Kotlin qui sera transpilé en JS ensuite.
Je cherche à supprimer TypeScript du code de mes SPA pour n'avoir que du Kotlin côté back, du Kotlin transpilé/compilé vers du JS ou vers WASM côté front et du DSL en Kotlin via Ktorm pour le SQL.
Bref un langage pour les contrôler tous.
@Kalvn pour exécuter du JS sur Node quand tu veux avoir un maximum de contrôles appliqués par le compilateur tu peux aussi tout coder en Kotlin et transpiler tes sources en JS. Tu as un plugin Gradle et un plugin Maven qui gèrent ça pour toi.
On a du mal à se rendre compte à quel point Kotiln change la vie avant de l'avoir adopté. Je pense que le gain du passage de Java/C#/TS vers Kotlin est même plus important que le gain du passage de C/C++/ASM vers Rust, c'est dire !
Et avec le REPL des JRE 17+, on peut écrire des scripts en Kotlin (au sens Bash du terme), et ça c'est trop cool ! <3
L'évolution de la demande de développeurs Kotlin est en plein boom en France 😁 :
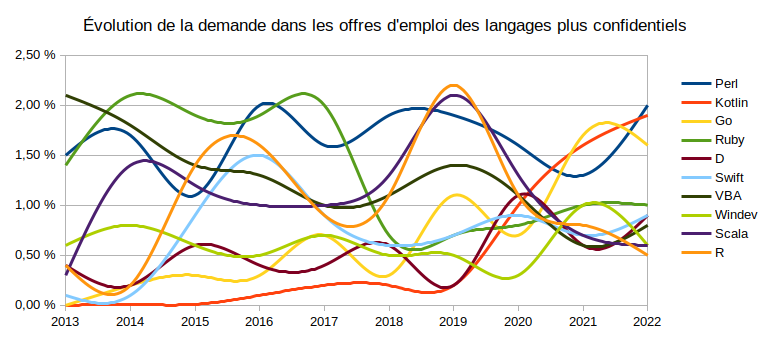
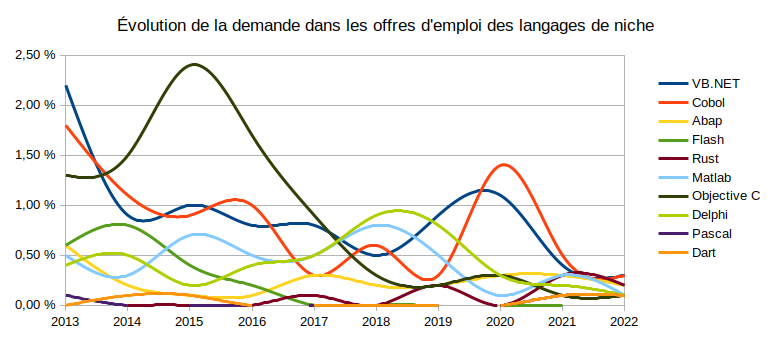
Rust ne suit pas encore mais c'est un résultat attendu puisque l'emploi est pour l'instant situé en Chine, en Corée et aux USA et l'étude se focalise sur la France. Au fil des mois, il devrait phagocyter tout doucement ses parts à C et surtout C++ 🤩 :
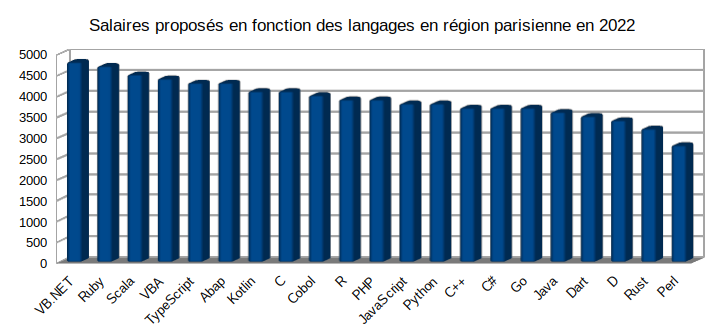
La bonne surprise c'est de voir que Kotlin se positionne très bien sur la grille des salaires bruts 🤑 :
Pour l'instant j'ai eu le nez creux avec Kotlin, il faut dire que le compilateur fait des choses époustouflantes, notament la preuve d'absence de de référencement de pointeurs (NullPointer) lors de la compilation, et que son API est merveilleuse comparée à Java (même si elle s'appuie dessus).
Il en va de même pour Rust, qui apporte tellement de choses qui manquent à C et C++, notamment la preuve d'absence de fuites memoire et de race-conditions dès la compilation ou encore un gestionnaire de paquets digne de ce nom.
Bref, attendons encore un peu avant de crier victoire mais pour l'instant, tout se profile comme il le faut pour moi et cela valait bien de s'investir autant 🥳.
Contexte
Depuis quelques jours, la tâche m'incombe de comparer les performances de la JRE face à du code natif, le benchmark porte principalement sur Kotlin vs Rust.
Depuis Java 17, les choses ont é-nor-mé-ment évoluées au point où en termes de temps de calcul CPU ou de débits I/O purs, la JRE est plus rapide que C/C++ ou Rust sauf si l'on active les options de compilation de C/C++/Rust qui retirent la portabilité des exécutables entre Intel et AMD.
L'idée est donc d'obtenir, au moyen du paramétrage de la JRE, le meilleur compromis entre :
- Les temps de calcul CPU
- La charge moyenne CPU
- Les débits I/O
- Les temps de latence I/O
- La quantité de mémoire consommée
- Les temps de démarrage
- Le poids total de l'application
- La capacité à être supervisé/debuggé
Ce poste va donc regrouper les différentes options à passer soit aux compilateurs Kotlin et Java, soit à la JRE elle-même, ainsi que les pré-requis matériels qui en découlent en expliquant le pourquoi du comment (ça va être long mais le cours est gratuit alors profitez-en 😘).
Pré-requis
Depuis Java 11, la JRE est prévue pour fonctionner de manière optimale sur du multi-threads avec une certaine quantité de mémoire (au minimum 2 threads CPU et 2 Go de RAM). Aussitôt qu'elle s'exécute sur un seul thread CPU/vCPU ou moins de 2 Go de mémoire, alors elle considère être en environnement contraint et va activer des stratégies d'exécution plus lentes afin de fonctionner correctement (notamment SerialGC).
Sur une architecture x64/Aarch64, il faut donc une configuration matérielle minimale afin de ne pas tomber dans ce mode d'exécution aux performances limitées.
C'est pourquoi toutes les options ci-après porteront sur un matériel disposant :
- De 4 threads CPU (2 physiques + 2 virtuels ou 4 physiques)
- De 8 Go de RAM (car sur du 64 bits, en-dessous, c'est du gâchis)
- D'un disque SSD ou NVMe (c'est-à-dire avec au moins 2 threads d'écriture/lecture simultanés)
Enfin, nous parlons ici de Java 17 et rien d'autre.
Quantité de mémoire réservée (non affectable à l'application)
Dans notre cas de figure, nous avons 8 Go à allouer de manière optimale. De ces 8 Go retranchons ce que nous ne pouvons pas prendre car pris par autre chose :
- La taille de l'OS + Services (System-D, SSH Pare-feu, fail2ban, borg backup, monitoring, etc) => 136 Mo
- La taille de la JRE qui est elle-même un programme => 24 Mo.
- Le taux d'espace réservé par la swappiness (chez moi 1%) => 80 Mo
- La marge d'erreur => 16 Mo
Soit un total de 256 Mo sur 8 Go qui ne seront jamais affectés à notre application.
Fonctionnement de Java 17
La mémoire est répartie en quatre zones :
- La Stack ou pile d'appels (il y en a une par thread).
- Le Young Space qui regroupe les espaces Eden et les Survivors où sont gérées les nouvelles instances.
- Le Tenured Space, aka Old Space, qui regroupe toutes les instances ayant survécus au GC dans le Young Space.
- Le Metaspace (qui reprend le rôle du PermGen) qui retrouve tout ce qui est statique, le byte-code compilé, les informations du compilateur JIT (Just In Time) et les méta-données de classes.
Depuis Java 8, on représente les nouvelles zones de la JRE par le diagramme suivant :

Dans notre cas de figure, ces zones vont se partager 8 Go - 256 Mo = 7 744 Mo. En sachant que la consommation réelle de la mémoire d'une JRE se calcule au moyen de l'addition suivante : [Taille de la pile d'appel x Nb Threads] + [Taille du Heap] + [Taille du Metaspace] + [Taille de la JRE (C-Heap)].
Choisir le bon Garbage Collector
Globalement trois choix s'imposent sur Java 17 :
G1 (Garbage-First)
- S'active via l'option
-XX:+UseG1GC. - À utiliser par défaut mais pour s'en servir de manière optimale il faut que votre application nécessite au moins 6 Go de mémoire OU qu'au moins 50% du heap contienne des objets encore en vie.
Shenandoah
- S'active via l'option
-XX:+UseShenandoahGC. - À utiliser si vous souhaitez minimiser le plus possible les temps de pause dus au GC (< 1 ms) OU que vous souhaitez des temps de pause semblables quelque soit la taille du heap entre 2 Go et 200 Go.
ZGC (expérimental)
- S'active via l'option
-XX:+UnlockExperimentalVMOptions -XX:+UseZGC. - À utiliser si votre application requiert plusieurs téraoctets de RAM (oui téra ou a minima quelques centaines de Go) OU que vous ayez besoin de régler le seuil de concurrence des cycles du GC parce que votre hardware dispose de trouze-mille threads matériels.
Je mets volontairement au rebus les GC trop lents ou dépréciés tels que Serial collector, Parallel collector, Concurrent Mark and Sweep et évidemment NoGC.
=> Dans notre cas de figure nous partirons sur Garbage-First / G1.
Paramétrage de la JRE
Toute la configuration de notre JRE se fera au moyen de la variable d'environnement JRE_OPTIONS qui sera passée en argument à la commande java. Par défaut nous exécuterons notre JRE en mode serveur.
Dimensionnement de la Stack
Nous avons un CPU à 4 threads. Dans un monde idéal, la JRE s'appuierait sur un pool de 4 threads CPU et chaque frameworks utiliserait un thread virtuel qui serait dépilé/traité par ceux du pool.
Mais nous ne vivons pas dans un monde idéal, nous allons donc limiter le nombre de threads de notre application à 16 threads physiques par threads CPU soit 4 x 16 = 64 threads au total.
Notre système ne disposant que de 8 Go de RAM, nous allons limiter la taille de chaque pile d'appels via l'option -Xss à 1 Mo soit 1 x 64 Mo = 64 Mo cumulés.
N.B : par défaut la JRE définit déjà une taille de pile d'appels à 1 Mo mais je préfère la forcer au cas où une mise à jour changerait cette valeur.
Cette limitation vient aussi du fait que je souhaite que le poids de la Stack ne dépasse pas 1% de la RAM. Il n'y a pas de raison particulière à cela mais afin de se représenter la chose, avec 1 Mo d'appels en cascade il est possible d'imbriquer dans le même algorithme :
- ~2 000 méthodes dont chaque signature expose 6 paramètres + un type de retour.
- ~3 900 méthodes dont chaque signature expose 3 paramètres sans type de retour.
Étant donné que je travail avec Jooby sur Netty il n'y aura pas de problème pour configurer le nombre de threads et la taille de la pile d'appel. Mais dans la pratique, il faut bien connaître ses frameworks ou tout profiler sinon.
Dimensionnement du Metaspace
Le Metaspace a pour comportement d'occuper tout l'espace restant afin d'éviter les OutOfMemory ; contrairement au PermGen que nous pouvions contraindre mais qui occupait l'espace du Heap.
Dans la pratique, le poids cumulé de tous les jars des frameworks que j'utilise pour un service RESTful est inférieur à 16 Mo mais une fois les jars décompressés ce sont ~40 Mo de fichiers répartis sur ~6 000 .class qui sont à charger.
En jouant avec les options -Xcomp, -Xbatch, XnoclassGC et -XCompileThreshold=1 j'ai forcé la JRE a compiler 100 % du bytecode en mémoire dans le Metaspace. Et en analysant le poids avec l'utilitaire JConsole, j'ai pu constater que 32 Mo étaient occupés.
Je suppose que la taille maximale du Metaspace devrait être égale au poids des .class + au poids des ressources chargées dans le classpath (même si a priori non). Comme mon système a beaucoup de RAM, je préfère ajouter une nouvelle fois 16 Mo de marge et ensuite profiler l'application pour déterminer si cette marge est toujours nécessaire.
Je vais donc passer la taille par défaut du Metaspace ainsi que la taille de ses partitions à 64 Mo. Je considère aussi que le Metaspace peut évoluer entre 5% et 95% de sa capacité avant d'être redimensionné à la hausse ou à la baisse.
Au final, la stratégie consistera à définir des options -Xmx et -Xms qui ne laisseront au Metaspace que les 64 Mo dont il aura besoin pour mon application. Évidemment, certains programmes codés en Spring Bouse réclameront facilement 100 Mo ou 200 Mo de Metaspace. Il faut donc mesurer l'espace occupé dans le pire cas de figure pour correctement paramétrer le reste.
Dimensionnement du Heap
Dans mon cas, ce sera facile. Il me suffit de reprendre la taille maximale disponible et de lui retrancher la taille du Metaspace, de la Thread Stack, de la JRE et de la marge d'erreur.
On obtient 7 744 - 64 - 64 - 24 - 16 = 7 576 Mo
Dimensionnement des zones du Heap
Comme vu plus haut, le Heap est décomposé en Young et Old spaces. Pour savoir quel espace allouer au Young Space (et donc à laisse au Old Space) il faut superviser l'application.
Dans mon cas de figure, comme j'ai appris à coder avec de petites instances immutables, imbriquées et jetables, j'ai besoin d'un gros Young Space par défaut, en sachant que celui-ci prendra toute la place qu'il peut dans le Heap s'il en a le besoin.
Sans profiling, je pars sur une répartition 3/4 Young et 1/4 Old, soit respectivement 5 682 Mo et 1 894 Mo sur les 7 576 Mo affectables. J'arrondis le 5 682 Mo à 5 680 Mo car ce sera plus pratique pour déclarer les ratios Eden vs Survivor.
Supervision de la JRE
La JRE produit elle-même des logs qui sont indispensables pour comprendre ses dysfonctionnement en production. L'idée est donc de définir une rolling policy ainsi qu'un fichier de sortie.
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=< number of log files >
-XX:GCLogFileSize=< file size >[ unit ]
-Xloggc:/path/to/gc.logParamètre de la ligne de commande
Au final nous obtenons ce script de démarrage
#!/usr/bin/env dash
## Mode server
JRE_OPTIONS="-server"
## Heap
* Nous avons min = max pour que la JRE s'affecte tout dès son démarrage et s'évite de perdre du temps aux resize
JRE_OPTIONS="${JRE_OPTIONS} -Xms7576m" # Taille minimale du Heap
JRE_OPTIONS="${JRE_OPTIONS} -Xmx7576m" # Taille maximal du Heap
## Young Space
JRE_OPTIONS="${JRE_OPTIONS} -XX:NewSize=5680m" # Taille par défaut du Young Space
JRE_OPTIONS="${JRE_OPTIONS} -XX:MaxNewSize=5680m" # Taille maximale du Young Space
## Thread Stack
JRE_OPTIONS="${JRE_OPTIONS} -Xss1m" # Taille de la Stack d'un thread sur 16
## Taille du Metaspace
JRE_OPTIONS="${JRE_OPTIONS} -XX:MetaspaceSize=64m" # Seuil au-delà duquel le Metaspace grossi
JRE_OPTIONS="${JRE_OPTIONS} -XX:MaxMetaspaceSize=64m" # Taille maximale du Metaspace avant un OutOfMemory
JRE_OPTIONS="${JRE_OPTIONS} -XX:MinMetaspaceFreeRatio=5" # Après un GC complet, pourcentage d'espace libre minimal du Metaspace avant son augmentation
JRE_OPTIONS="${JRE_OPTIONS} -XX:MaxMetaspaceFreeRatio=95" # Après un GC complet, pourcentage d'espace libre maximal du Metaspace avant sa réduction
## Logs
JRE_OPTIONS="${JRE_OPTIONS} -Xloggc:/var/log/my-app/jre.log" # Emplacement du fichier de log
JRE_OPTIONS="${JRE_OPTIONS} -XX:+UseGCLogFileRotation" # Mise en place d'une rotation des fichiers de log
JRE_OPTIONS="${JRE_OPTIONS} -XX:NumberOfGCLogFiles=10" # Nombre maximum de fichiers de logs
JRE_OPTIONS="${JRE_OPTIONS} -XX:GCLogFileSize=100m" # Taille maximale d'un fichier avant rotation
JRE_OPTIONS="${JRE_OPTIONS} -XX:+HeapDumpOnOutOfMemoryError" # Dump de la mémoire en cas de OOM
JRE_OPTIONS="${JRE_OPTIONS} -XX:HeapDumpPath=/var/log/my-app/oom.log" # Chemin vers le fichier
JRE_OPTIONS="${JRE_OPTIONS} -XX:OnOutOfMemoryError='shutdown -r '" # Commande a exécuter en cas de OutOfMemory
JRE_OPTIONS="${JRE_OPTIONS} -XX:+UseGCOverheadLimit" # Limitation des temps GC avant qu'un OOM ne soit levé
## Optimisation du byte-code
JRE_OPTIONS="${JRE_OPTIONS} -XX:+UseStringDeduplication" # Evite d'instancier plusieurs fois la même String
JRE_OPTIONS="${JRE_OPTIONS} -XX:+OptimizeStringConcat" # Utilise un StringBuffer pour concaténer des String quand c'est possible mais pas fait par le développeur
java ${JRE_OPTIONS} -cp ${CLASSPATH} ${mainClass}Une introduction à ce qu'il est possible de mesurer à l'aide de l'utilitaire jcmd embarqué dans les JDK.
Tout est dans le titre. Je suis en train de comparer plusieurs choses actuellement :
-
Le surcoût que représente la JRE 17 sur une application Kotlin.
-
Le gain qu'apporte une JRE 17 custom produite à l'aide de l'utilitaire JLink.
-
Les performances de (1) et (2) face à la même application codée en Rust, en termes de consommation mémoire et d'opérations par seconde.
-
Les nouvelles options que la JRE prends en paramètre et leurs effets sur le CPU, la mémoire et le débit.
Le tuning de JRE a toujours été compliqué, mais pour obtenir une JRE de 30 Mo optimisée comme il faut, il y a encore plus de choses à connaître et comprendre qu'avant. Damned !
Alors la situation est un poil plus compliquée que ce qui est dit.
Sur les vieilles versions de Java, Oracle fait effectivement la chasse aux licences. Mais il s'agit d'un modèle privateur donc normal.
Sur les versions 8 à 19 de Java, le modèle est basé sur trois composantes. Une JVM (machine virtuelle Java) avec les dernières features, une JVM avec les derniers correctifs de stabilité ou de sécurité, une JVM gratuite.
Quelle est l'astuce ? Simple, on ne peut pas avoir ces trois composantes simultanément.
C'est-à-dire que soit on veut avoir les dernières features et être stable/securisé et alors on paie.
Soit on ne paie pas mais dans ce cas on a :
- Soit les dernières features sur une JVM instable/non-sécurisée
- Soit on a une JVM avec 3 ans de retard sur les features mais qui est gratuite et stable/sécurisée.
Enfin, rappellons que Java est libre (GPLv2) et que les projets Eclipse Temurin, Apache et OpenJDK ont fusionné pour donner naissance à une JVM 100% libre Adoptium. Donc bye bye Oracle.
Remarque : si vous codez en Kotlin, puisque le compilateur peut cibler la version de la JVM que vous utilisez et vous fournir les dernières features sans que la JVM ne soit a jour, alors autant partir sur la dernière LTS gratuite de Java et être tranquille côté sécurité / stabilité.
Sinon Kotlin se compile très bien en WASM et en natif aussi <3
L'utilitaire JavaDoc ne fonctionne pas avec du code Kotlin (normal me direz-vous). Heureusement, Jetbrains fourni Dokka sous la forme de plugin Maven et Gradle permettant de faire la même chose.
Les annotations et syntaxes Dokka diffèrent un peu de la JavaDoc, voici un résumé :
@param Identique à JavaDoc
@property Pour documenter un attribut
@constructor Pour documenter un constructeur primaire
@return Identique à JavaDoc
Pour faire un lien vers une _classe/method/autre_ simplement écrire ceci
/** Je veux faire un lien vers [MaClass] **/
et Dokka fera le jobAttention, Java 6 n'étant plus supportée les dépendances kotlin-stdlib-jdk7 et kotlin-stdlib-jdk8 n'existent plus (puisque c'est Java 8 la version minimale requise pour Kotlin à présent).
Il faut donc les remplacer par kotlin-stdlib. Une migration simple qui va poser de nombreux problèmes à certains, sans aucun doute.
Je cite :
« À mesure qu'Android passe de C/C++ à Java/Kotlin/Rust, nous nous attendons à ce que le nombre de vulnérabilités liées à la sécurité de la mémoire continue de diminuer. Vivement un avenir où les bogues de corruption de la mémoire sur Android seront rares », a conclu Google.
Rust et Kotlin sont deux superbes langages (avec une petite préférence pour Kotlin). J'ai pourtant quelques reproches à faire à l'un et à l'autre mais quand je vois que le marché avance vers eux à grands pas, autant vous dire que j'en suis toute chose <3
Que du beau sous le soleil.
En un exemple court et simple :
package com.memorynotfound;
import java.lang.management.ManagementFactory;
import java.lang.management.RuntimeMXBean;
public class GetUpTime {
public static void main(String... args) throws InterruptedException {
RuntimeMXBean rb = ManagementFactory.getRuntimeMXBean();
System.out.println("Up time: " + rb.getUptime() + " ms");
}
}Edit
En complément il y a ce projet sur lequel jcefmaven est basé.
Problème
- J'ai besoin de développer un client lourd.
- Je préfère mourir que de me remettre à Swing ou d'utiliser JFX (dont la réputation d'API instable avait fait le tour du web il y a quelques années).
Solution
Cette dépendance Maven qui intègre un moteur de rendu WebKit :
<dependency>
<groupId>me.friwi</groupId>
<artifactId>jcefmaven</artifactId>
<version>105.3.36</version>
</dependency>Avec le tuto pour Java
//Create a new CefAppBuilder instance
CefAppBuilder builder = new CefAppBuilder();
//Configure the builder instance
builder.setInstallDir(new File("jcef-bundle")); //Default
builder.setProgressHandler(new ConsoleProgressHandler()); //Default
builder.addJcefArgs("--disable-gpu"); //Just an example
builder.getCefSettings().windowless_rendering_enabled = true; //Default - select OSR mode
//Set an app handler. Do not use CefApp.addAppHandler(...), it will break your code on MacOSX!
builder.setAppHandler(new MavenCefAppHandlerAdapter(){...});
//Build a CefApp instance using the configuration above
CefApp app = builder.build();Ceci se fait en deux étapes :
1) Déclarer la property dans le plugin Surefire comme suit
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>LAST_SUREFIRE_VERSION</version>
<configuration>
<systemProperties>
<property>
<name>name-the-property-will-have-in-test</name>
<value>${my-property}</value>
</property>
</systemProperties>
</configuration>
</plugin>2) La récupérer en tant que propriété système dans les TU
val property = System.getProperty("name-the-property-will-have-in-test")Kotiln, Rust et Python progressent et de plus en plus de développeurs les adoptent (et c'est très bien).
J'ai été une grande utilisatrice de Python il y a un peu plus d'une quinzaine d'années lorsque je travaillais en labo sur du Data-Mining (l'ancêtre du Machine Learning). J'avais laissé de côté Python pour trois raisons à l'époque :
- Les problèmes de performance.
- Les problèmes d'outillage autour du build.
- Le fait que les programmes écrits en Python, pour être rapides, doivent utiliser des libs écrites en C, et donc avec un code orienté procédure.
Aujourd'hui, si je devais produire un système temps-réel et très peu énergivore, je partirais sur Rust.
Dans tous les autres cas de figure, je prendrais Kotlin sur OpenJDK ou Kotlin native (via le compilateur Kotlin-native ou GraalVM).
Par contre Python n'est plus du tout dans ma liste car pour moi à présent, si l'exécution d'un langage n'est pas prouvée à la compilation, c'est un stop immédiat. La majorité des développeurs n'écrivant pas de tests et maîtrisant mal le code (en tout cas en industrie) c'est indispensable.