L'évolution du nombre de morts du COVID-19 sur ces 120 derniers jours à travers le monde.

Popcorn.js est une lib de lecture de média audio/vidéo dans le navigateur. J'essaie de voir si l'outil permet de lire un flux découpé en chunk (comme les tubes le font si bien).
Un tuto expliquant comment fonctionne la balise vidéo de HTML5. Attention, le tuto n'est pas parfait, je recommande de le compléter par celui-ci de l'agence AlsaCréations qui explique les "vrais" attributs qu'il faut mettre dans la balise <video> (vrai au sens W3C du terme) et éventuellement celui-ci du site OpenClassRooms.
Et un lien intéressant portant sur les connexions P2P en WebRTC avec HTML5.
Je vais rentrer directement dans le vif du sujet en prenant argument par argument et en répondant à chaque fois. Puis j'apporterai les miens à la fin.
1) Les bus applicatifs permettraient de coder en évènementiel.
Oui mais ça ne veut pas dire que c'est la seule technologie permettant de le faire. Vous en connaissez sûrement une autre : les requêtes AJAX sur HTTP. Vous savez ce truc à la base de tous les internets "modernes" sorti en 1996.
Par essence une requête AJAX est asynchrone et c'est lorsque le serveur notifie le client qu'il a traité sa demande (ce qui est la définition même d'un évènement) qu'une fonction de call-back est invoquée.
2) Passer par un bus applicatif réduirait le couplage entre les services.
En général on me sort cet argument face à RESTful ce à quoi je réponds : le degré de couplage est le même.
Effectivement en RESTful ce qui compte c'est le chemin utilisé et un fichier JSON qui contient les données. Il ne s'agit pas là d'invoquer une méthode via RMI, ni d'employer la même technologie côté client et côté serveur, il s'agit d'envoyer un fichier texte contenant les bonnes informations sur une URL. Wouah mais quel couplage ! #Unbelievable
Nous sommes déjà au degré utile et essentiel de découplage. Commencer à vouloir s'abstraire de l'URL est un non-sens d'autant qu'elle se retrouvera quand même dans les messages des bus comme Kafka mais sous une autre forme : le type du message.
Je m'explique : pour qu'un message soit dépilé par le bon service, il faut qu'il soit typé (ie. je contiens tel contenu et j'incarne telle demande), or le typage d'une demande en RESTful c'est ni plus ni moins que l'URL. Avec les bus applicatifs comme Kafka, nous représentons ce typage sous la forme d'une entrée de type clef-valeur dans un header mais cela revient à la même chose que de contacter une URL. C'est juste moins facile à relire car les protocoles sont binaires et non textuels (cf. KafkaMessage) donc ça paraît "plus découplé" mais ça ne l'est ni plus ni moins.
3) Les bus applicatifs permettraient de gérer des queues de messages.
En réalité cet argument n'en est pas un. Nous avons ajouté de la puissance de calcul dans le bus dont le rôle sera d'encaisser les pics de charge ; or pourquoi ne pas affecter cette puissance de calcul (en générale inhumaine lorsque nous parlons d'un cluster Kafka) directement dans les µ-services ? (ndr. qui sont eux aussi un anti-pattern d'architecture)
Dit autrement, nous préférons affecter de la puissance de calcul à des unités de stockage de messages, rajoutant ainsi des latences et augmentant les coûts d'infrastructure plutôt qu'aux unités de traitement qui fournissent elles des calculs utiles.
Je suis favorable aux queues lorsqu'elles sont à l'intérieur d'une application, car elles aident à mettre en place des algorithmes de calculs mutli-threads et parallèles pour ainsi tirer parti de 100% des hardwares mutli-cpus / multi-cores.
Au niveau inter-applicatif c'est une très mauvaise idée car cela fait reposer nos SI sur l'élément le moins fiable du monde : le réseau.
4) Les bus applicatifs seraient plus sécurisés en forçant une rupture protocolaire.
L'argument du changement de protocole dépend de comment fonctionne le bus et de son implémentation. Par exemple les bus qui travaillent en SOAP sur HTTP fonctionnent sur HTTP... Comme nos requêtes REST en somme... #ChangementDeProtocoleSur20
Ensuite, la sécurité ce n'est pas qu'une simple histoire de protocole, c'est toute l'architecture qui doit être pensée pour être résistante aux attaques. Cet argument laisse accroire que la sécurité est une chose facile et que nous aurions magiquement augmenté le niveau juste par la présence d'un sacro-saint bus, ce qui est faux.
Enfin, en quoi un changement de protocole sécurise quoi que ce soit ? Si j'envoie un message via un bus, quoi qu'il arrive ce dernier sera traduit dans un format interprétable par l'application, si je peux effectuer une injection parce que l'application tolère les injections, je pourrai quand même attaquer le système.
Souvent, on me rétorque à cet argument que le bus peut faire des contrôles anti-injections par exemple, mais ce sont les mêmes personnes qui me disent de l'autre côté qu'un bon bus reste au niveau du réseau et qu'il doit être neutre au niveau application : décide-toi camarade.
Pour moi ce qui transporte un message ou une requête ne doit transporter que le message ou la requête et ne rien faire d'autre. Quand j'envoie ou que je reçois une lettre par la poste je ne veux pas que la poste ouvre ma lettre et en modifie le contenu "pour me protéger". #Censure Pour mes applications c'est pareil, je décide seule de ce qui est une attaque et de ce qui est une demande, pas le bus, donc pas de sécurité à son niveau. #SegragationOfConcerns
5) Le monitoring réseau est plus facile avec un bus.
Le bus est un endroit centralisé par lequel tout transite, donc enregistrer qui s'adresse à qui semble plus simple que faire la même chose dans un réseau maillé à la sauce internet où n'importe qui peut contacter n'importe qui d'autre.
Alors cela est vrai lorsque les bus ne sont faits que d'une seule instance... Or si une seule et unique machine peut encaisser toute la charge de vos messages, déjà je vous pose la question de l'intérêt d'avoir mis en place un bus pour un SI aussi peu complexe avec une volumétrie aussi faible mais admettons...
En général les bus applicatifs sont de très gros clusters avec des systèmes de réplication inter-instances... Les gens qui me parlent de monitoring vont me dire que "grâce au bus je sais qui envoie des messages au cluster de mon bus et qui reçoit des messages du cluster de mon bus". Ok... Mais que se passe-t-il à l'intérieur du cluster ? Quel trajet le message a-t-il effectué dans cette #BoiteNoire ?
En y regardant de plus prêt nous nous rendons compte qu'il existe une case à l'intérieur de laquelle nous n'analysons plus rien et nous décrétons que cette case n'est pas à superviser puisque c'est le bus lui-même ; ce qui revient à superviser un routeur.
Or ne regarder que ce qui est extérieur au bus se rapporte à monitorer la périphérie du SI, c'est-à-dire nos services et c'est déjà chose possible avec des logs produits par les services eux-mêmes + ELK pour un coût et une complexité d'infrastructure dix fois moindre.
Je sais que Kafka est plus intelligente et permet de se monitorer elle-même, mais cela ne répond pas à la question du nombre d'instances supplémentaires à gérer du fait de sa seule présence, ni même de l'expertise que cela requiert ou encore de la manière dont Kafka va contraindre la façon de coder les services.
6) Les bus me permettraient de changer un service sans impacter les autres.
L'idée sous-jacente est de dire que comme tout le monde parle au bus alors les services ne se connaissent pas entre-eux. Il devient donc possible de changer un service sans devoir patcher les autres.
En réalité ce coût de transformation est déporté non pas pendant la mise à jour du service mais au moment de la migration du bus A vers un autre bus B.
Sauf que l'économie de ces petits coûts traités au fil de l'eau se métamorphosera en supra-giga-facture lors de la big-bang transformation qui consistera à sortir totalement le SI du bus A. C'est évident, puisque tout le monde parlant au bus, aussitôt que l'on changera de bus, il faudra mettre à jour tout le monde avec la complexité et le risque que ce genre de "migration" impose. Vous le sentez l'anti-pattern du point de vue du CTO ou d'une DSI ?
Je préfère disposer d'une communication ad-hoc entre plusieurs services REST s'appuyant sur des Swagger faisant office de contrat d'interfaçage. Ainsi tant que tout le monde parle le bon JSON, ça marche point.
Pas de protocole particulier, pas de lib "kafka-client" à tirer dans mon application, pas de dépendances vers des tiers, juste des fichiers textes ayant une structure (CSV, JSON, XML, YAML, etc) et que j'envoie ou reçois sur le réseau ; avec des mises à jours petites, fréquentes et réalisées en continue pour faire virer notre paquebot de SI sereinement.
Je peux en plus choisir un format adapté qu'il soit plat (properties) ou arborescent (JSON) là ou Kafka m'impose du plat en clef-valeur. Cette contrainte rend juste votre vie difficile pour représenter une hiérarchie d'objets, heureusement ça n'arrive que tout le temps...
Il faut bien comprendre que lorsqu'un Swagger change pour ajouter un nouvel attribut par exemple, il faut alors changer tous les clients. Mais c'est également le cas avec des bus comme Kafka ! En effet, si un message nécessite une valeur supplémentaire, il faut que tous les clients émettant ce message intègrent cette nouvelle valeur. Mais alors où se trouve le découplage des bus par rapport à REST ? Où se trouvent el famoso "mise à jour sans impact" ? Réponse : nulle part, c'est un mythe.
Nous voici arrivés à la partie contre-arguments (qui va être courte car j'en ai marre d'écrire) :
Les bus sont des SPOF (Single Point Of Failure) mais pourquoi ?
Au niveau du réseau
Comme tout passe par le bus, alors si le bus tombe tout tombe. C'est la raison pour laquelle Kafka a émergé ; puisque si un nœud Kafka tombe, alors il en existe d'autres pour assurer le travail et l'engouement pour Kafka est à mon sens le témoin du fait que les bus mono-instances étaient encore plus des anti-patterns. Mais quid des difficultés d'administration de Kafka ?
Je rappelle qu'un service doit déclarer les adresses de tous les nœuds Kafka pour se connecter au cluster (au cas où le seul nœud déclaré aurait lâché). Je dois donc paramétrer mon application pour qu'elle ait une connaissance de l'infrastructure alors que celle-ci devrait être agnostique de cette infrastructure. Nous revenons en arrière de 20 ans (promis je ferai un poste expliquant en quoi Docker fait la même chose vis-à-vis du build lié à la sécurité).
Le nombre d'instances à administrer augmentent mais pas seulement... Le type d'instances aussi !
Et oui il faut administrer les instances du bus en plus des instances applicatives mais en plus il faut disposer d'admin-sys ayant des compétences sur les applications ET sur le bus !
Alors du point de vue du cabinet de conseil c'est merveilleux puisque je peux fourrer encore plus de prestas ! #Money Mais du point de vue du CTO ou de la DSI, c'est mon porte-feuille qui se fait mettre à mal.
Et là je ne parle pas que de compétences, arguons que chaque instance tourne sur du hardware en dernier recours et que ce hardware a un coût. Plus d'instances => Plus de hardware ou du hardware plus gros et donc plus cher ! C'est le second effet kiss-cool au porte-monnaie.
Mais il y en a un troisième !! Il faut que je recrute des développeurs qui maîtrisent le bus. Vous savez les développeurs Kafka par exemple... Sauf que compétences en plus => tarifs plus élevés. Et cela engendre des difficultés de recrutement d'une part et une sensibilité accrue au turner-over d'autre part surtout quand l'expert Kafka nous quitte...
Les schémas du SI intégrant un bus masquent l'horreur de la réalité.
Avant les bus applicatifs, les architectes fournissaient des schémas avec plein de boites et encore plus de flèches le tout partant dans tous les sens. C'était alors triviale de constater l'ampleur du grand merdier et donc de réclamer une simplification du SI aux architectes dont le travail était manifestement défaillant.
Avec un bus, nous nous retrouvons avec les boites applicatives en périphérie de ces schémas et une plus grosse au centre : celle du bus lui-même. Là le schéma est propre, harmonisé, au moyen une belle structure en étoile où chaque composant ne s'adresse qu'au bus... #PowerPointSur20
Soyons clairs, c'est le même bordel à l'intérieur de la grosse boi-boite qui représente le bus que ça ne l'était avant sans la présence du bus. Sauf que ce souk devient invisible quand on ne se rend pas sur le terrain, en observant les flux et le code... Mais ce que le CTO ne voit pas ne lui pose pas de problème n'est-ce pas ?
Illustration du problème AVANT

Illustration du problème APRES

Comment identifier l'endroit où la complexité est la plus dense ? Comment y affecter des personnes et mesurer sans effort l'ampleur des difficultés qu'elles vont affronter si tous ces schémas avec ces flèches dans tous les sens ont été effacés du regard ? Comment justifier les coûts budgétaires aussi élevés à chaque mise à jour alors que notre SI paraît si simple, si joli, si sophistiqué avec sa structure en étoile dans de beaux Power-Point animés ?
Si certains architectes aiment autant les bus, je pense que c'est parce qu'ils peuvent montrer à quel point ils brillent, leurs schémas devenant clairs, limpides, dignes des experts qu'ils sont au vu de leurs tarifs. Et toute la difficulté retombera alors sur le dos des développeurs, vous savez ces "tocards" payés à pas cher et importés de l'étranger... De parfaits coupables pour des experts influents et bien-pensants face à la certitude que les devs soient des incompétents.
Je résumerais ma position sur un principe : KISS (Keep It Simple, Stupid !). Cela vaut pour du code, cela vaut aussi pour le SI.

Edit : comme me la souligné @Chlouchloutte, aucune source n'est citée dans l'article et impossible d'en trouver un qui corrobore cette information sur internet via moteur de recherche (français, anglais et italien).
Par contre je suis tombée sur cet article en anglais qui expliquait début avril que le ministère de l'éducation japonais se tâtait effectivement pour rouvrir les écoles.
Bref, je positionne le site "rapport-de-force" comme une source de qualité niveau "mouais". Cependant ça n'enlève rien à mon avis sur la question et décrit ci-dessous.
Je cite :
Réouverture des écoles au Japon ==> flambée des nouvelles infections. En 10 jours, le nombre de cas de Covid-19 a DOUBLÉ dans le pays.
Et la France veut ré-ouvrir ses écoles le 11 mai. J'ai peur.
Je vais être limpide : ne risquez pas votre vie pour une entreprise qui vous remplacera en une semaine si vous veniez à mourir.
Le COVID-19 tue. Le taux mortalité constatée (c-à-d. nombre de contaminés détectés en hôpital sur nombre de morts constatées de ces contaminés en hôpital) ne fait que monter. Le ministère français de la santé se targuait de pouvoir limiter le taux de mortalité à 2 % en hôpital, or le 20 avril 2020 le taux de mortalité du COVID-19 en hôpital dépassait les 13 %. #MaisWTF!
Soyons clairs, les oligarques envoient les pauvres en guerre, les font travailler jusqu'à épuisement en usine, leurs balancent leurs forces de l'ordre-par-la-force pour les agresser et les mutiler lorsqu'ils manifestent, notre seule option est de constituer ensemble une conscience de classe et de leur dire : non, allez faire le boulot vous-même si c'est si important que ça selon vous.
Je suis ingénieure informaticienne à mon compte, j'exerce en télétravail sans problème, la qualité des livrables et les temps de livraison se sont incroyablement améliorés depuis le confinement, pourquoi ? Parce que les développeurs sont enfin exemptés de toutes ces réunions inutiles et pourtant si précieuses à un management remplaçable par une boite mail... Néanmoins cela n'empêche pas mon client de parler de "nous déconfiner" et de nous demander comment organiser ça... Mais LOL !
Ma réponse :
- Le gouvernement a menti depuis le début sur cette affaire.
- Le gouvernement prends les plus mauvaises décisions depuis le début sur cette affaire.
- Le gouvernement nous prend pour des imbéciles, des débiles, des crétins depuis le début sur cette affaire.
Pour les sources, je vous invite vraiment à regarder les trois reportages du youtubeur Trouble Fait sur la question du COVID-19 :
- Loué soit Raoult et sa Sainte Chloroquine! (ou pas)
- Quand Castaner et Buzyn détruisaient l'hôpital à coup de Fakenews !
- Coronavirus : Leur gestion est pire que le Covid-19 !
Il faut les envoyer se faire voir, point !
Dit autrement : imaginez que vous êtes devant un bol contenant 100 M & M's. Imaginez que seulement deux de ces M & M's soient empoisonnés et mortels (le fameux 2%)...
Question : vous tentez votre chance et prenez quand même des M & M's dans le bol ? Mieux encore, vous tentez d'en ramener quelques uns à la maison pour votre époux, votre épouse ou vos enfants puissent y goûter ? Hein ? HEIN ??? Non je ne crois pas !
Et pourtant le déconfinement c'est ça, c'est ramener à la maison quelque chose qui puisse vous tuer et si par chance vous y êtes résistant rien n'indique alors que ceux qui vous sont les plus chers le soient.
Et ne me parlez pas de "sauver l'économie" ! Je rappelle que crise il y a seulement s'il y a un écart entre production et demande, or ici la production a baissé en même temps que la demande : ça n'est pas une crise économique. Par contre c'est une crise du capitalisme, nous avons produit tout un tas de merdes dont personne n'a jamais eu besoin et que plus personne n'achète. C'est une première dans l'histoire de l'humanité, nous sommes en crise non pas parce que nous n'arrivons pas à produire pour survivre mais parce que nous avons trop produit sans pouvoir écouler les stocks !
Et ne me parlez pas de la chute du PIB non plus ! Je rappelle que chaque génération précédente a vécu avec un PIB moins important que celui actuel (mythe de la croissance illimitée). Pour info, il y a à peine 5 ans, en 2015 donc, le PIB était inférieur de 200 milliards d'euros à celui actuel ! Une économie à croissance perpétuelle n'est utile qu'aux banques, aux fonds d'investissements et aux milliardaires mais appauvrie toutes les classes laborieuses !
Je n'ai pas l'impression que c'était difficile de vivre pour moi en 2015 et pourtant le PIB était si bas et la croissance proche de zéro (cf. début des taux directeurs négatifs et fameuse "crise du crédit" où les taux d'emprunts sur 25 ans étaient à 1,6%).
Comment éduquer une population aussi débile, autant manipulée et même prête à se sacrifier pour une chose aussi irréelle et intangible que l'économie ?
Via Sebsauvage.

En une image :

Toshiba, Seagate et Western Digital pris la main dans le pot de confiture. En substance il y a trois technologies d'enregistrement sur les plateaux en cuivre des disques durs, du plus lent au plus rapide nous avons : le SMR, le PMR et le CMR.
Le SMR a l'avantage de permettre de stocker plus sur un même plateau en cuivre (donc réduire les coûts de production en augmentant les marges) mais est plus lent (jusqu'à un facteur 3 apparemment) pour l'enregistrement que le CMR qui est le standard sur le marché.
Donc revendre des disques en tant que CMR avec du SMR dernière à des gens qui souhaitent faire autre chose que du stockage froid (archivage)... C'est d'une part mentir sur les caractéristiques techniques de son produit (ce qui est illégal) et c'est d'autre part ce que l'on appelle purement et simplement une arnaque.
Du coup comme ces trois entreprises se partagent 95% du marché mondiale il est quasiment impossible de les boycotter... #Génial
@Animal : les Western Digital sont comment tu disais ?

Wear the damn masks, people. Even if you feel fine.
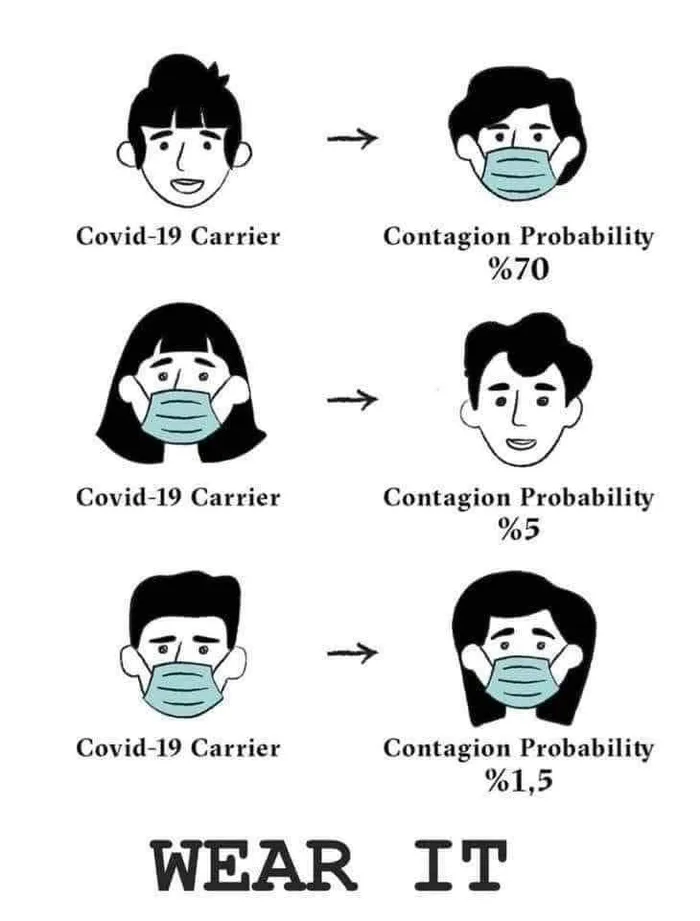

Je cite @Sebsauvage :
Un peu violent mais sûrement efficace: Quand PortSentry détecte des connexions sur les services fictifs qu'il expose, il bloque l'IP source.
Du coup via Sebsauvage.

Tout un tas de recommandations pour optimiser Docker. Cela va des temps de construction des conteneurs en passant par leur taille et allant jusqu'au runtime. Des choses sûrement déjà dites mais ce type de synthèse sert toujours.
Via Memiks.


La page recense deux méthodes la première via ffmpeg et la seconde via mkvmerge (disponible dans le paquet mkvtoolnix sous Debian) ce qui nous donne :
# Via FFMPEG (commande à jouer plusieurs fois pour des chunks de même durée )
ffmpeg -i ORIGINALFILE.mp4 -acodec copy -vcodec copy -ss 0 -t 00:15:00 OUTFILE-1.mp4
ffmpeg -i ORIGINALFILE.mp4 -acodec copy -vcodec copy -ss 00:15:00 -t 00:15:00 OUTFILE-2.mp4
ffmpeg -i ORIGINALFILE.mp4 -acodec copy -vcodec copy -ss 00:30:00 -t 00:15:00 OUTFILE-3.mp4
# Ou via MVKMerge pour des chunks de même taille
mkvmerge -o outputprefix --split 1G origfile.mp4Je remercie @Animal de m'avoir parlé de VLC qui fait également le taf avec un tuto disponible ici mais malheureusement pas en ligne de commande.

Un article en trois parties vraiment très bon et qui tombe pile poil au moment où je suis en train de regarder pour réduire la taille des images Dockers de plusieurs projets.
Je sens que ça va intéresser @Philou :
- Lien vers la partie 1.
- Lien vers la partie 2.
- Lien vers la partie 3.
Via Liandri.

Supprimer tous les bloatwares des constructeurs Android. Mon OnePlus va y passer est certain !!

Traduction :
Ne comparez pas votre chapitre 1 au chapitre 30 d'un autre.


Tout un tas d'exemples en Spring Boot notamment un simple "Hello World!".
Pour toi @animal
Oh cette citation :
J'ai besoin d'intimité. Non pas parce que mes actions sont douteuses, mais parce que votre jugement et vos intentions le sont.
Dit autrement, j'ai besoin de vie privée non pas parce que j'ai quelque chose à cacher, mais parce que je ne peux pas vous faire confiance à vous, ceux qui m'épient et me surveillent en permanence car c'est un comportement bizarre et anormal.
Je cite :
Les bases de données relationnelles sont plus adaptées à des requêtes de type "trouver toutes les entités de type X" grâce aux structures internes des tables. Cela est d'autant plus vrai lorsqu'il s'agit de réaliser des opérations d’agrégation sur toutes les lignes d'une table.
L'exemple que donne la Wikipédia est très bien puisqu'il part d'un modèle relationnel maîtrisé pour représenter la même chose sous la forme d'un graphe.

{kind=link}
Concept :
- Vous démarrez une
main()vide (enfin qui contient juste le point suivant). - Vous charger un class-loader dynamique qui lui va charger vos JARS ou les répertoires de vos classes directement.
- A chaque mise à jour de ces fichiers, les classes et ressources du classpath seront rechargées à chaud dans l'espace mémoire de la JVM.
Je vais me coder une petite lib qui va se charger de charger l'application à la place de la main() et permettre les démarrages à chaud. #Luv