Historiquement, pour un serveur web performant en Rust j'utilisais Actix. J'en avais parlé ici et comme je le soulignais dans le poste, Actix est orienté annotation-driven-bullshit.
Mon besoin n'a pas changé, je veux du code explicite, WYSIWYG, sans macro/processor. Et depuis quelques temps je lorgnais du côté de Xitca qui prend littéralement Actix à revers en utilisant les mêmes couches sous-jacentes mais en virant le côté annotation-driven-bullshit.
Exemple
use xitca_web::{handler::handler_service, middleware::Logger, route::get, App};
async fn index() -> &'static str {
"Hello world!!"
}
fn main() -> std::io::Result<()> {
App::new()
.at("/", get(handler_service(index)))
.enclosed(Logger::new())
.serve()
.bind("localhost:8080")?
.run()
.wait()
}Nous sommes très proche de Kooby en Kotlin, Jooby en Java, Flask en Python ou Sinatra en Ruby et c'est exactement ce que je recherche car cela veut dire que l'on peut décorer l'API afin de rendre le framework invisible du point de vue du code.
Merci à la communauté derrière Xitca <3

Titre PutaclickSur20.
Il s'agit en réalité d'une n-ème faille de sécurité de Windows, ici via l'utilitaire cmd.exe qui lance une invite de commande, et qui affecte tous les langages de programmation parce que (contrairement à Linux), je cite :
L'API Windows ne fournit qu'une seule chaîne de caractères contenant tous les arguments, laissant au processus créé la responsabilité de les diviser. La plupart des programmes utilisent la chaîne d'exécution standard argv en C, ce qui permet d'obtenir un comportement cohérent en matière de division des arguments. Cependant, cmd.exe possède sa propre logique de découpage des arguments, qui nécessite un échappement personnalisé par la bibliothèque standard Rust [et des autres langages].
Mais comme les communautés qui développent langages libres et interopérables sont de vrais professionnels eux, les langages compensent à la place de Microchiotte ce que Microchiotte aurait dû codé correctement dans Windows...
Bref, Rust est déjà patché. Si vous ne voulez pas être affectés par cette faille de sécurité, travaillez sur un OS digne de ce nom et quittez les boites qui vous forcent à bosser sur OSX ou Windows.
Tout est dans le titre. Comment réduire et optimiser son build Rust.
Je découvre un nouveau serveur web pour Rust. Bien plus rapide qu'Actix, son interfaçage avec le code est le même.
Je vais le tester et voir si cela vaut la peine de l'utiliser dans les nouveaux projets.
Je travaille en ce moment sur deux projets, un en Java/Kotlin pour des clients, un second en Rust pour des besoins internes, et j'ai réalisé la chose suivante :
- En Java/Kotlin, le langage est fait pour vous aider mais vous allez vous battre contre les frameworks.
- En Rust, les frameworks sont faits pour vous aider mais vous allez vous battre contre le langage.
C'est incroyable à quel point le borrow checker vous pousse à écrire du code procédurale et mécaniquement intestable. Dès l'instant où l'on souhaite passer par des traits tout devient ultra compliqué. Dernièrement je me suis faite avoir en utilisant des Rc et des RcCell sur un code qui allait devenir multi-thread #Horreur
Pour moi, casser le couplage entre deux composants via une interface/trait est IN-DIS-PEN-SABLE mais Rust pousse à définir des structures comme contrat d'interfaçage principal entre deux pans de code.
Forcément, le langage se transforme en enfer dès l'instant où l'on souhaite dépendre d'un trait et non d'une structure (c'est pourtant le 'I' de SOLID, dépendre des Interfaces mais pas des Implémentations).
En même temps je l'avais déjà dit par le passé, le paradigme fonctionnel pur est un cancer métastasé car l'expressivité de la syntaxe donne le sentiment que des tests ne sont pas nécessaires or c'est toujours faux.
Et j'ai suffisamment souffert de Java dans ma vie pour haïr le fait de devoir mocker/instancier/déclarer quarante-douze-mille trucs avant de pouvoir tester une simple fonction.
Bref, deux ans sur Rust à temps partiel et je me vois retourner dans le RustBook tous les 4 mois pour y chercher un truc #Pénible alors qu'en Kotlin ça ne m'arrive jamais.
@Kysofer tu cherchais une implémentation de Twig en Rust mais Twig est inspiré de Jinja2 donc Tera qui est une implémentation de Jinja2 en Rust est compatible avec tes composants Twig écrits pour Pebble 😋 #Cadeau
Du coup nous avons la stack
- Kotlin + Pebble + Jooby + H2DB/PostreSQL pour les projets en clientèle.
- Rust + Tera + Actix + SQLite pour les projets internes.
Mon objectif étant qu'en une seule étape, je dispose en sortie de deux binaires, un pour Linux x64 et un autre pour ARM 64 (aarch64).
Pour faire simple, les workspaces de Cargo sont l'équivalent des modules de Maven.
Pour définir une configuration commune à tous les workspaces il faut ajouter ceci dans le Cargo.toml à la racine du projet :
[package]
name = "sotoestevez_medium"
version = "0.1.0"
[workspace]
members = ["add_trait", "beginning_tips", "generify_with_compiler_errors", "modules", "scoped_threads" ]
[workspace.package]
edition = "2021"
authors = ["Soto Estévez <ricardo@sotoestevez.dev>"]
description = "Demos of the articles at https://medium.com/@sotoestevez"
documentation = "https://medium.com/@sotoestevez"
readme = "./README.md"
homepage = "https://www.sotoestevez.dev"
repository = "https://github.com/kriogenia/medium"
license = "MIT OR Apache-2.0"Puis activer l'héritage dans chaque Cargo.toml des workspaces :
[package]
name = "add_trait"
version = "0.1.0"
edition.workspace = true
authors.workspace = true
description = "Dissecting Rust Traits to Learn Their Secrets"
documentation = "https://betterprogramming.pub/dissecting-rust-traits-to-learn-their-secrets-839845d3d71e"
homepage.workspace = true
repository.workspace = true
license.workspace = trueCela marche aussi avec les versions des dépendances. Dans le parent on déclare ceci :
[workspace.dependencies]
num = { version = "0.4", default-features = false }
vector2d = "2.2"
rand = "0.8.5"Et dans les enfants ceci :
[dependencies]
num = { workspace = true, default-features = true }
vector2d.workspace = true
[dev-dependencies]
rand = { workspace = true, features = [ "log" ] }Je dois écrire un µ-service en Rust et j'ai cherché pas mal de serveurs web permettant de le faire. Évidemment, la première chose que les moteurs de recherche nous remontent c'est Hyper. Pour faire simple, Hyper est une serveur HTTP 1/2 qui s'appuie sur le pool de threads asychrone Tokio.
Problème, Hyper reste assez bas niveau. Je recherchais donc quelque chose aux performances équivalentes mais bien plus simple d'utilisation et je suis tombée sur Actix qui à l'air de faire le café. Je regrette uniquement la reprise du annotation-driven-bullshit via les macros déclaratives mais en dehors de cela, tout va bien.
Exemple de hello world en Actix / Rust :
use actix_web::{get, web, App, HttpServer, Responder};
#[get("/")]
async fn index() -> impl Responder {
"Hello, World!"
}
#[get("/{name}")]
async fn hello(name: web::Path<String>) -> impl Responder {
format!("Hello {}!", &name)
}
#[actix_web::main]
async fn main() -> std::io::Result<()> {
HttpServer::new(|| App::new().service(index).service(hello))
.bind(("127.0.0.1", 8080))?
.run()
.await
}Je fais beaucoup de Rust ces derniers temps et je cherchais un framework qui puisse m'aider à produire mes requêtes SQL en sachant que je voulais tout sauf une horreur orientée structures comme peut l'être le couple JPA / Hibernate.
Au détour d'un coup de fil, @LapinFeroce me parle de Diesel qui est l'équivalent de Ktorm mais pour Rust. Autant vous dire qu'à la simple lecture de l'exemple de la home page j'étais déjà conquise 😻
En un code d'exemple :
// use macro_rules! <name of macro>{<Body>}
macro_rules! add {
// macth like arm for macro
($a:expr,$b:expr) => {
// macro expand to this code
{
// $a and $b will be templated using the value/variable provided to macro
$a+$b
}
}
}
// Usage in code
fn main(){
// call to macro, $a=1 and $b=2
add!(1,2);
}Attention à ne pas abuser de la méta-programmation car cela peut augmenter significativement les temps de compilation.
Il implémente l'interface log qui est l'équivalent de SLF4J de Java/Kotlin mais pour Rust.
Il a la particularité de pouvoir se configurer directement dans le code en plus de fichier Yaml :
use log::LevelFilter;
use log4rs::append::console::ConsoleAppender;
use log4rs::append::file::FileAppender;
use log4rs::encode::pattern::PatternEncoder;
use log4rs::config::{Appender, Config, Logger, Root};
fn main() {
let stdout = ConsoleAppender::builder().build();
let requests = FileAppender::builder()
.encoder(Box::new(PatternEncoder::new("{d} - {m}{n}")))
.build("log/requests.log")
.unwrap();
let config = Config::builder()
.appender(Appender::builder().build("stdout", Box::new(stdout)))
.appender(Appender::builder().build("requests", Box::new(requests)))
.logger(Logger::builder().build("app::backend::db", LevelFilter::Info))
.logger(Logger::builder()
.appender("requests")
.additive(false)
.build("app::requests", LevelFilter::Info))
.build(Root::builder().appender("stdout").build(LevelFilter::Warn))
.unwrap();
let handle = log4rs::init_config(config).unwrap();
// use handle to change logger configuration at runtime
}Et sa façade log reprend l'API de SLF4J mais sous forme de macros :
let world = "World";
trace!("Hello {}!", world);
debug!("Hello {}!", world);
info!("Hello {}!", world);
warn!("Hello {}!", world);
error!("Hello {}!", world);À voir pour les performances, mais l'idée de reprendre l'API d'une façade qui a fait ses preuves pour y coller l'implémentation que l'on veut derrière est la bienvenue !
En trois étapes :
- Exécuter la commande
cargo install --color=always --force grcovpour récupérer l'utilitaire (qui sera automatiquement ajouté à votre PATH user). - Démarrer Intellij IDEA.
- Installer / Activer le plugin Rust depuis la market place.
Enjoy
En résumé, la méthode du trait doit prendre en paramètre un
&Fn(X) -> Yet non un
Fn(X) -> YSinon, Rust ne peut pas garantir l'exécution de la fonction puisque le trait prendrait possession de la fonction. Or cette closure peut être un pointeur sur fonction, ce qui retirerait la propriété de cette dernière de sa structure.
Code d'exemple
fn fun_test(value: i32, f: &dyn Fn(i32) -> i32) -> i32 {
println!("{}", f(value));
value
}
fn times2(value: i32) -> i32 {
2 * value
}
fn main() {
fun_test(5, ×2);
}Explication
Il y a trois types possibles de fonctions :
- Fn qui ne peut pas modifier l'objet qu'elle capture.
- FnMut qui peut modifier l'objet qu'elle capture.
- FnOnce la plus restrictive. Ne peut être appelée qu'une seule fois car une fois invoquée elle se consomme elle-même ainsi que l'objet qu'elle capture.
Ce qui est super c'est que la documentation possède un tableau comparant la complexité des différentes structures en fonction des cas d'utilisation.
Tout est dans le titre.
Différences entre les enums Option et Result en Rust.
Il n'y a pas à dire, à chaque fois que je code et où le langage m'oblige à utiliser des Optional, je me dis que c'est un langage pourri. Et ceci inclus Rust malgré tout le bien que je pense de lui 😤 !
La meilleure façon de gérer les cas de nullité se trouve dans Kotlin 🥰, TypeScript et Groovy. Le type Optional est une technique archaïque et verbeuse quand on vient du null-check de Kotlin.
Mais bon j'ai déjà expliqué par le passé en quoi le paradigme fonctionnel pure était un cancer métastasé 🤮. Et entre C++ et Rust pour de la programmation système il n'y a plus vraiment de discussion à cette heure, donc faisons-nous violence avec les Optional.
Mon rêve serait un langage natif reprenant la syntaxe de Kotlin (sauf tout ce qui touche aux getter/setter) avec le borrow checker de Rust et qui produise des binaires natifs. Je pense que je peux rêver encore longtemps 🥲
L'évolution de la demande de développeurs Kotlin est en plein boom en France 😁 :
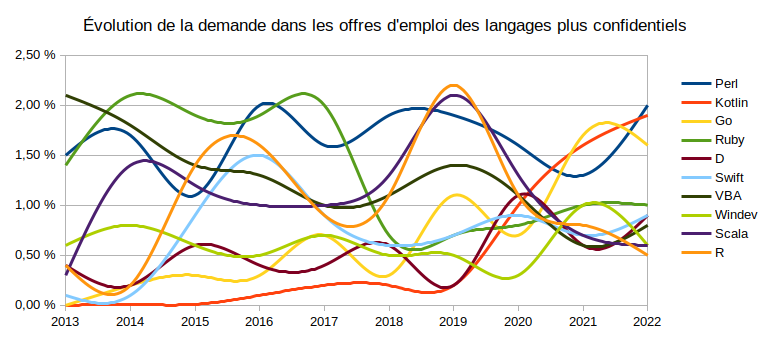
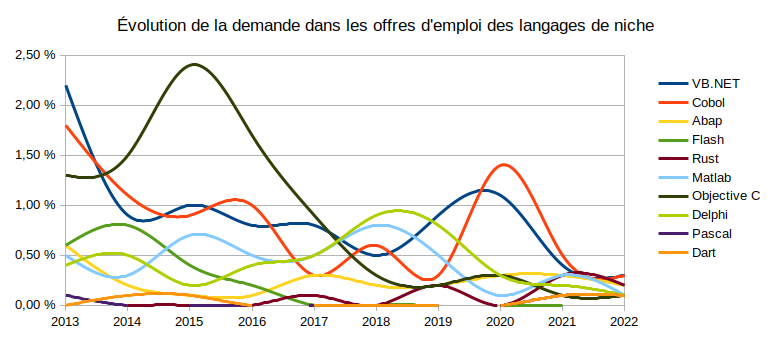
Rust ne suit pas encore mais c'est un résultat attendu puisque l'emploi est pour l'instant situé en Chine, en Corée et aux USA et l'étude se focalise sur la France. Au fil des mois, il devrait phagocyter tout doucement ses parts à C et surtout C++ 🤩 :
La bonne surprise c'est de voir que Kotlin se positionne très bien sur la grille des salaires bruts 🤑 :
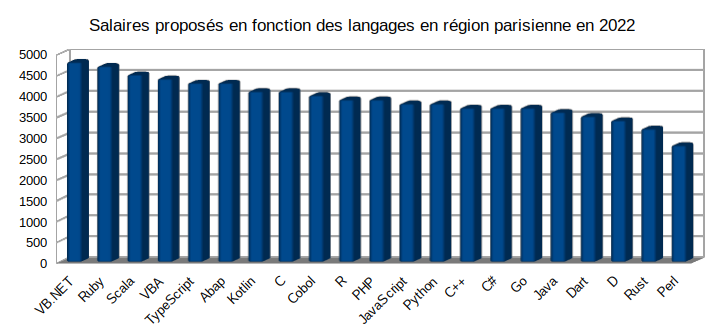
Pour l'instant j'ai eu le nez creux avec Kotlin, il faut dire que le compilateur fait des choses époustouflantes, notament la preuve d'absence de de référencement de pointeurs (NullPointer) lors de la compilation, et que son API est merveilleuse comparée à Java (même si elle s'appuie dessus).
Il en va de même pour Rust, qui apporte tellement de choses qui manquent à C et C++, notamment la preuve d'absence de fuites memoire et de race-conditions dès la compilation ou encore un gestionnaire de paquets digne de ce nom.
Bref, attendons encore un peu avant de crier victoire mais pour l'instant, tout se profile comme il le faut pour moi et cela valait bien de s'investir autant 🥳.
L'idée est de tirer 100% des optimisations possibles sur une architecture donnée pour ne cibler qu'elle mais ne plus être portable en contrepartie.
Il suffit de déclarer la variable d'environnement RUSTFLAGS comme ceci :
# Cibler la plateforme sur laquelle est construit le binaire
RUSTFLAGS="-C target-cpu=native"
# CPU Intel
RUSTFLAGS="-C target-cpu=skylake"
# CPU AMD
RUSTFLAGS="-C target-cpu=znver2"