Oh merci, une cheat sheet sur les CSS Grid !
Via shaarliGor.

La seule chose qu'il me manque en Rust ce sont des classes. Depuis que j'ai adopté le style de programmation OOP de Yegor Bugayenko, penser en objet et non en procédurale-qui-se-fait-passer-pour-de-l'objet me semble évident.
Ceux qui décrètent que l'OOP ne marche pas ne parviennent tout simplement pas à penser en Objet. Cela revient à dire que la récursion terminale ne fonctionne pas parce que l'on ne parvient pas à penser un algorithme itératif en invocation récursives et sans encombrer la pile d'appels.
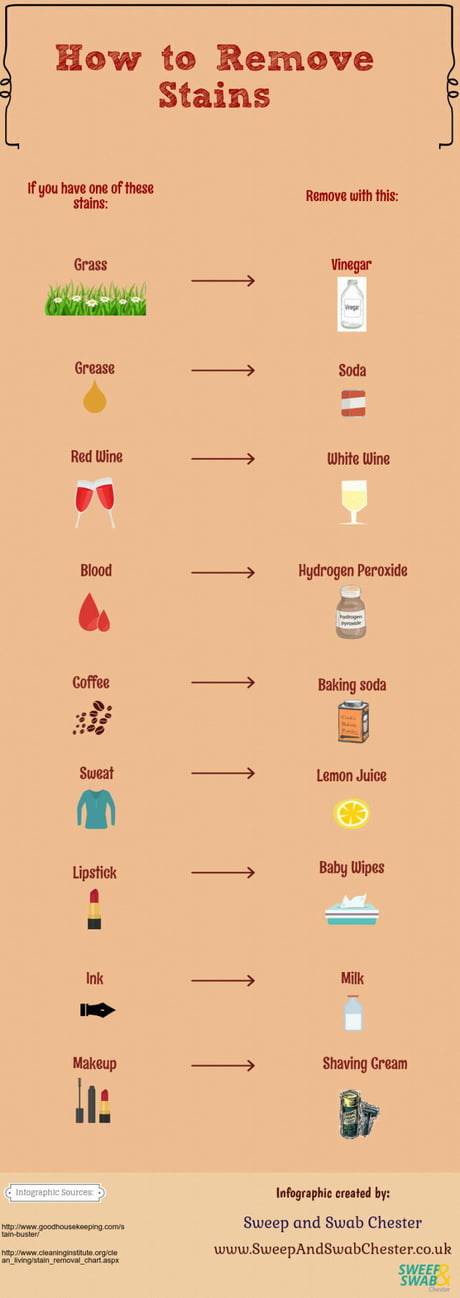
De nouveaux trucs pour nettoyer vos tâches.

Un résumé expliquant comment utiliser facilement H2BD (création d'une connexion, ajout de la base en dépendance Maven, création d'un pool de connexion, connectivité avec Hibernate & JPA, URL à utiliser, etc.
Voici quelques exemples :
Cas pour rendre les données persistantes sur le disque :
# Pour stocker les données de la base dans le répertoire TEST de votre home
jdbc:h2:~/TEST
# Pour stocker les données de la base dans le répertoire /data/TEST
jdbc:h2:/data/TEST
URL pour l'écriture en mémoire (données non persistantes) :
# Permet d'avoir plusieurs connexion pour une même instance (processus) :
jdbc:h2:mem:test
# Permet de n'avoir qu'une seule connexion (schéma anonyme et privé) :
jdbc:h2:mem:Changer le dialect SQL de H2DB pour employer celui d'une autre base :
La liste des modes de compatibilité est disponible ici
# Pour Apache Derby
jdbc:h2:mem:MON_SCHEMA;MODE=Derby
# Pour DB2
jdbc:h2:mem:MON_SCHEMA;MODE=DB2
# Pour MySQL
jdbc:h2:mem:MON_SCHEMA;MODE=MySQL;IGNORECASE=TRUE
# Pour Oracle
jdbc:h2:mem:MON_SCHEMA;MODE=Oracle
# Pour PostgreSQL
jdbc:h2:mem:MON_SCHEMA;MODE=PostgreSQLExécution de scripts SQL au démarrage de la base :
# Pour exécuter un script SQL au démarrage de l'instance de la base :
jdbc:h2:mem:test;INIT=create schema if not exists test\;runscript from '~/sql/init.sql'Le mec est vraiment un super connard

{kind=link}
{kind=link}